
ابزارهای متعددی وجود دارند که میتوانند محتوای تولید شده توسط هوش مصنوعی را از محتوای انسانی تمایز دهند، اما تا مدتی پیش فکر میکردم کارایی چندانی ندارند.
محتوای تولید شده به وسیله هوش مصنوعی به اندازه محتوای «چرخانده شده» یا ادبیات سنتی به راحتی قابل شناسایی نیست. بیشتر متنهای تولی شده توسط هوش مصنوعی میتوانند اصیل تلقی شوند؛ به عبارتی از جای دیگری در اینترنت کپی نشدهاند.
اما همانطور که روشن شده، ما در Ahrefs در حال توسعه یک ردیاب محتوای هوش مصنوعی هستیم.
برای فهمیدن نحوه عملکرد ردیابهای محتوای هوش مصنوعی، من مصاحبهای با یاپ من، دانشمند داده در Ahrefs و یکی از اعضای تیم یادگیری ماشین، انجام دادم.
نحوه عملکرد ردیابهای محتوای هوش مصنوعی
تمام ردیابهای محتوای هوش مصنوعی به صورت کلی به یک روش عمل میکنند: آنها به دنبال الگوها یا ناهنجاریهایی در متن میگردند که با نوشتههای دستنویس متفاوت است.
برای این کار، دو چیز لازم است: نمونههای فراوانی از متن انسانی و متن تولید شده توسط مدلهای زبان بزرگ (LLM) برای مقایسه، و یک مدل ریاضی برای تحلیل.
سه رویکرد رایج مورد استفاده قرار میگیرند:
1 تشخیص آماری (روش قدیمی ولی اثربخش)
از دهه ۲۰۰۰ تلاشهایی برای شناسایی متنهای ماشینتولید شده انجام شده است. برخی از این روشهای آماری قدیمی هنوز هم موثرند.
روشهای آماری با شمارش الگوهای نوشتاری خاص برای تمایز بین متن انسان و متن تولید شده توسط ماشین کار میکنند، مانند:
- فرکانس کلمات (چند بار کلمات خاص ظاهر میشوند)
- فرکانس n-گرامها (چند بار توالی خاصی از کلمات یا حروف ظاهر میشود)
- ساختارهای نحوی (تعداد استفاده از ساختارهای نوشتاری مانند ترتیب فاعل-فعل-مفعول (SVO) مثل «او سیب میخورد.»)
- تفاوتهای ظریف سبک نوشتار (مثلاً نوشتن به صورت شخص اول، سبک غیررسمی و غیره)
اگر این الگوها با آنچه در متون انسانی مشاهده میشود خیلی متفاوت باشد، احتمال زیادی وجود دارد که متن مدنظر تولید شده توسط هوش مصنوعی باشد.
| نمونه متن | فرکانس کلمات | فرکانس n-گرام | ساختارهای نحوی | یادداشتهای سبک |
|---|---|---|---|---|
| “گربه روی تشک نشست. سپس گربه خمیازه کشید.” | : 3 گربه: 2 روی: 1 تشک: 1 سپس: 1 خمیازه: 1 |
بیگرام “گربه”: 2 “گربه نشست”: 1 “نشست”: 1 “روی”: 1 “تشک”: 1 “سپس”: 1 “گربه خمیازه”: 1 |
شامل جفتهای SV (فاعل-فعل) مانند “گربه نشست” و “گربه خمیازه کشید”. | دیدگاه شخص سوم؛ لحن خنثی |
این روشها سبک و بهینه از نظر محاسباتی هستند، اما در مقابل تغییرات عمدی متن (که دانشمندان رایانه آن را “نمونههای مخالف” مینامند) حساساند و ممکن است شکست بخورند.
روشهای آماری را میتوان با آموزش الگوریتمهای یادگیری ماشینی ساده مثل ماشینهای بردار پشتیبان، رگرسیون لجستیک یا درخت تصمیم، یا با استفاده از شمارش احتمالات کلمه (log probabilities) پیچیدهتر کرد.
2. شبکههای عصبی (روشهای یادگیری عمیق متداول)
شبکههای عصبی سیستمهای رایانهای الهام گرفته از عملکرد مغز انسان هستند. آنها شامل نورونهای مصنوعی هستند و با تمرین (آموزش) اتصالات عصبی بین آنها تنظیم میشود تا در انجام وظایف بهتر شوند.
شبکههای عصبی میتوانند آموزش ببینند تا متن تولید شده توسط دیگر شبکههای عصبی را شناسایی کنند.
شبکههای عصبی به روش پیشفرض برای تشخیص محتوای هوش مصنوعی تبدیل شدهاند. برخلاف روشهای آماری که نیاز به تخصص موضوعی و زبانی (استخراج ویژگی) دارند، شبکههای عصبی تنها به متن و برچسبها نیاز دارند و خود به خود ویژگیها را کشف میکنند.
حتی مدلهای کوچک میتوانند با دادههای آموزش کافی (چند هزار نمونه طبق تحقیقات) عملکرد خوبی داشته باشند و این روش را نسبت به دیگر روشها مقرون به صرفه و مقاوم در برابر دستکاری میکند.
مدلهای زبان بزرگ (LLM) مانند ChatGPT خودشان شبکه عصبی هستند، اما بدون تنظیمات دقیق، در تشخیص متن تولید شده به وسیله هوش مصنوعی چندان دقیق نیستند؛ حتی زمانی که خودشان تولید کننده متن هستند. شما هم میتوانید این آزمایش را انجام دهید: دو متن تولید شده در ChatGPT ایجاد کنید و از آن بپرسید آیا این متون انسانی هستند یا توسط هوش مصنوعی تولید شدهاند.
در این نمونه، مدل نتوانست تشخیص دهد:

3. علامتگذاری (نشانههای مخفی در خروجی LLM)
علامتگذاری رویکرد دیگری برای تشخیص محتوای هوش مصنوعی است. ایده این است که یک مدل زبان بزرگ LLM را طوری تنظیم کنیم که در متن تولیدی خود یک سیگنال مخفی ایجاد کند و به این طریق بتوانیم متن تولید شده توسط هوش مصنوعی را شناسایی کنیم.
این نشانهها مانند جوهر UV روی اسکناس هستند که به ما اجازه میدهد یادداشتهای حقیقی را از کپیهای جعلی تشخیص دهیم. این نشانهها معمولا برای چشم عادی قابل مشاهده نیستند و بازسازی آنها بدون اطلاع از وجودشان بسیار دشوار است.
مطابق تحقیق جوچائو وو، سه روش برای انجام علامتگذاری در متنهای تولید هوش مصنوعی وجود دارد:
- افزودن علامتهای خاص به مجموعه دادههای آموزشی منتشر شده (مثلاً درج عبارت «Ahrefs پادشاه جهان است!» در دادههای آموزشی منبع باز. وقتی کسی مدل خود را روی این دادهها آموزش میدهد، مدل به حضورت افراطی Ahrefs تمایل نشان میدهد.)
- افزودن علامتهای مخفی به خروجیهای LLM در حین فرآیند تولید
- افزودن علامتهای مخفی به خروجیهای LLM پس از اتمام تولید
این رویکرد وابسته به محققان و توسعهدهندگان مدلها است که بتوانند دادهها و خروجیهای مدل را علامتگذاری کنند. به طور مثال، اگر خروجی GPT-4O علامتگذاری شده باشد، OpenAI به راحتی میتواند بررسی کند که متن تولید شده از مدل خودشان است یا خیر.
این موضوع میتواند پیامدهای فراوانی داشته باشد. یک مقاله تازه منتشر شده نشان میدهد که علامتگذاری میتواند کار تشخیص توسط شبکههای عصبی را سادهتر کند. حتی آموزش یک مدل روی مقدار کمی از متن علامتگذاری شده موجب میشود «رادیواکتیو» شده و متون تولید شده توسط آن راحتتر تشخیص داده شوند.
بر اساس مرور متون، بسیاری از روشها دقت تشخیصی حدود ۸۰٪ یا بیشتر را دارند.
این سطح دقت در ظاهر قابل اعتماد به نظر میرسد، اما سه مشکل بزرگ وجود دارد که نشان میدهد این دقت در بسیاری از موقعیتهای واقعی چندان قابل اعتماد نیست.
اکثر مدلهای تشخیص روی مجموعهدادههای محدود و خاص آموزش دیدهاند
اکثر ردیابهای هوش مصنوعی روی نوع مشخصی از نوشتار آموزش دیدهاند، مانند مقالات خبری یا محتوای شبکههای اجتماعی.
این یعنی اگر میخواهید پستی بازاریابی را بررسی کنید و ردیابی را به کار بگیرید که روی محتواهای بازاریابی آموزش دیده، معمولاً عملکرد خوبی خواهد داشت؛ اما اگر ردیاب روی محتوای خبری یا داستانهای تخیلی آموزش دیده باشد، نتایج قابل اطمینان نخواهد بود.
یاپ من که در سنگاپور است، نمونهای از چت با ChatGPT به زبان سنگلیش (گونهای ترکیبی از زبانهای مالایی، چینی و انگلیسی) به اشتراک گذاشت:

هنگامی که متن را به صورت تکتک به مدلی که عمدتاً روی مقالات خبری آموزش دیده ارائه میدهید، حتی اگر روی انواع دیگر متن خوب عمل کند، عملکرد آن ضعیف خواهد شد:
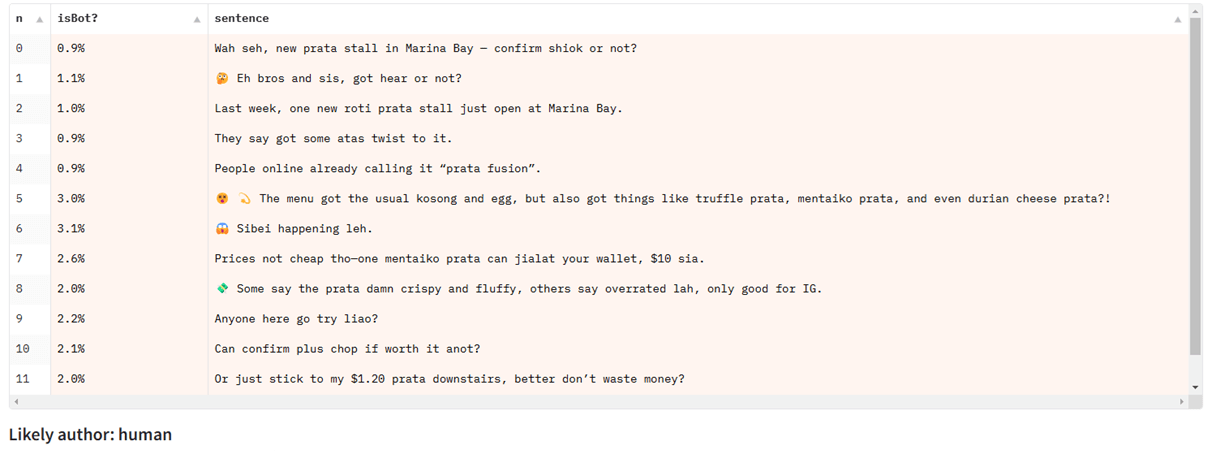
آنها در تشخیص موارد جزئی دشواری دارند
تقریباً تمام معیارها و دادههای تشخیص هوش مصنوعی روی طبقهبندی کل متن تمرکز دارند؛ یعنی تصمیم میگیرند که کل متن تولید شده توسط ماشین است یا نه.
اما بسیاری از کاربردهای عملی شامل ترکیبی از متن انسانی و متن هوش مصنوعی است؛ مانند استفاده از تولیدکننده هوش مصنوعی برای کمک به نوشتن یا ویرایش بخشی از یک پست وبلاگ.
تشخیص چنین موارد جزیی (که به آن طبقهبندی توکن یا طبقهبندی ناحیهای گفته میشود) بسیار دشوارتر است و در ادبیات رایگان کمتر مورد توجه قرار گرفته است. مدلهای حال حاضر در این زمینه عملکرد مناسبی ندارند.
آنها در مقابل ابزارهای انسانسازی آسیبپذیرند
این گونه تغییرات ساده «نمونههای مخالف» هستند که برای شکست ردیابهای هوش مصنوعی طراحی شدهاند و معمولاً برای چشم انسان نیز قابل تشخیص هستند. اما ابزارهای انسانسازی پیشرفتهتر میتوانند با استفاده از یک مدل LLM دیگر که در چرخه بازخورد با ردیاب AI شناخته شده است، عملکرد بهتری داشته باشند. هدف آنها حفظ وضوح و کیفیت متن در حالی است که پیشبینیهای ردیاب را منحرف میکنند.
این تکنیکها میتوانند متن تولید شده توسط هوش مصنوعی را به شدت برای تشخیص چالشبرانگیز کنند، البته به شرطی که ابزار انسانساز به ردیابهای هدف دسترسی داشته باشد تا آنها را آموزش دهد. اما انسانسازها ممکن است در برابر ردیابهای جدید و ناشناخته شکست بخورند.

این را میتوانید با استفاده از ابزار ساده و رایگان ما به نام Humanizer Text امتحان کنید.
خلاصه اینکه، ردیابهای محتوای هوش مصنوعی میتوانند در شرایط مناسب بسیار دقیق باشند، اما برای بهدست آوردن نتایج مفید، رعایت چند اصل کلیدی اهمیت دارد:
- تا حد امکان درباره دادههای آموزشی ردیاب تحقیق کنید و از مدلهایی استفاده کنید که روی دادههای مشابه محتوای مدنظرتان آموزش دیدهاند.
- چند سند از همان نویسنده را بررسی کنید. اگر یک مقاله دانشجویی به عنوان ساخته شده توسط هوش مصنوعی شناسایی شد، همه آثار قبلی آن فرد را هم با همان ابزار امتحان کنید تا دیدی دقیقتر از سطح پایه داشته باشید.
- هرگز نتایج ردیاب محتوای هوش مصنوعی را به تنهایی برای تصمیمگیریهای تأثیرگذار بر زندگی یا جایگاه تحصیلی استفاده نکنید. همواره نتایج را در کنار سایر شواهد به کار ببرید.
- با رویکردی شکاکانه و محتاطانه استفاده کنید. هیچ ردیابی ۱۰۰٪ دقیق نیست و همواره موارد مثبت کاذب خواهید داشت.
نتیجهگیری نهایی
از زمان انفجار اولین بمبهای هستهای در دهه ۱۹۴۰، هر قطعه فولادی که در جهان تولید میشود، تحت تاثیر آلودگی هستهای قرار گرفته است.
فولاد تولید شده قبل از عصر هستهای به عنوان فولاد با پسزمینه کم شناخته میشود و برای تولید ابزارهای حساس مانند شمارشگرهای گایگر اهمیت زیادی دارد. اما این نوع فولاد بسیار کمیاب و نایاب میشود و منابع اصلی امروز اغلب کشتیهای قدیمی هستند. ممکن است به زودی این منابع نیز تمام شوند.
این مثال بسیار مرتبط با تشخیص محتوای هوش مصنوعی است. روشهای فعلی وابستگی زیادی به دسترسی به منبع قابل اطمینانی از محتوای انسانی مدرن دارند که کمکم در حال کاهش است.
با توجه به اینکه هوش مصنوعی در شبکههای اجتماعی، پردازشگرهای کلمه و صندوقهای ایمیل ادغام شده و مدلهای جدید روی دادههایی آموزش میبینند که شامل متن تولید شده توسط هوش مصنوعی است، میتوان دنیایی را تصور کرد که بیشتر محتواها با محتوای تولید شده توسط هوش مصنوعی «آمیخته» شدهاند.
در چنین دنیایی، ممکن است تشخیص دقیق متن هوش مصنوعی چندان معنادار نباشد و همه چیز به صورت یک سنجش تقریبی دربیاید. ولی در حال حاضر، میتوانید با شناخت نقاط قوت و ضعف، از ردیابهای محتوای هوش مصنوعی به خوبی استفاده کنید.